Qwen3-1.7B-Wiki: Multi-turn RL to play the WikiGame
This post explores training a small language model (Qwen3-1.7B) to play the Wikipedia game through multi-turn reinforcement learning. A baseline performance of 13.5% was improved to 49.4% through SFT followed by Group Relative Policy Optimization (GRPO), but was unable to beat GPT4.1-mini or DeepseekV3. Model scale remains a fundamental constraint for tasks requiring complex multi-turn planning and adaptation, suggesting that architectural limitations cannot currently be fully overcome through training methodology alone.
Intro
LLMs have shown remarkable capabilities in solving complex reasoning tasks, but can smaller models learn to navigate multi-turn problems through reinforcement learning?
The wiki game/wiki racing game/wiki links game/six degrees of wikipedia is a game where players must navigate from one Wikipedia article to another using intermediate article links only, the goal is usually to do this in the fewest steps or the fastest time. If you've ever played before, you'll notice that most articles can be reached in surprisingly few steps. Consider the case of Gymnobela rotundata (sea snail species) ➡️ Exploding animal which can be achieved in just 3 steps.
 Source: Six Degrees of Wikipedia
Source: Six Degrees of Wikipedia
A simple strategy is to find a way to a "big" article with many outbound links like United States or Youtube and branch off closer to the domain of the target article. I would wager that most humans could solve 99% of wiki game pairs in under 12 steps using this approach and even fewer steps for an optimal strategy (a 2018 post suggests this to be closer to 3 to 4 on average). Unsurprisingly, LLMs can perform fairly well in the game since it mostly boils down to making connections between different topics.
Data
There are two sets of data utilized:
- English wikipedia articles containing the full list of outbound links
- Article pairs to run the game with. e.g. Gravity ➡️ Royal Canadian Mounted Police or Nvidia ➡️ Impressionism
Fortunately, the Wikimedia foundation has provided a structured snapshot of English Wikipedia from September 2024. We'll just do some processing to extract the urls from the nested sections. This ended up being ~14GB when stored in DuckDB due to large number of articles (~7 million) and links in each article.
It's also important here to make sure that we filter out dead links to prevent the model from clicking on them. Dead links are tricky to tackle due to the sheer number of articles, so the lazy way is to filter them out (i.e. check for existence in the database) as needed whenever we pass the links of the current article to the model.
As for the second dataset, the WikiSpeedruns website contains over 1300 different prompts that real humans have played and lists some statistics like the shortest path length (and the solution path) and average clicks that could serve as a reasonable proxy for how difficult a given pair is.
Data validation
Let's make sure the article pairs we've gathered actually have valid paths. The game is fundamentally a graph problem (BFS or a modified bi-directional BFS) but since we already know a valid path (thanks to human players!), we just need to run through this path and check that every article is valid/exists and has a link to the subsequent article in the chain. If the chain is broken, then we can do a BFS to the end article and verify that at least one path exists. Running this for all the pairs shows that they all have a valid path between them.
Environment
Task Formulation
Why does the Wiki game make a good RL task?
- Real knowledge application Models must leverage their training on Wikipedia data and general world knowledge while learning new navigation strategies
- Verifiable outcomes The task is trivially verifiable. Even if a given task has a large number of possible solutions as long as it can be verified, the model can learn from it. This applies not just to simple RL environments like gsm8k, puzzles (wordle, NYT connections, sudoku, etc) but also to potentially more complex tasks like protein structure prediction or algorithm optimization (AlphaEvolve).
- Scalable difficulty The task difficulty and complexity can be very easily varied depending on the model and/or capabilities we are testing
- Easy: For a given article, provide the full list of outbound article links and no other content.
- Medium: For a given article provide all section contents, but urls are embedded within the text. For example, we can formulate each article section such that links appear in markdown format. Below, the abstract section of Matrix is presented
In [mathematics](https://en.wikipedia.org/wiki/Mathematics), a **matrix** (pl.: **matrices**) is a [rectangular](https://en.wikipedia.org/wiki/Rectangle) array of [numbers](https://en.wikipedia.org/wiki/Number) or other [mathematical objects](https://en.wikipedia.org/wiki/Mathematical_objects) with elements or entries arranged in rows and columns, usually satisfying certain properties of [addition](https://en.wikipedia.org/wiki/Matrix_addition) and [multiplication](https://en.wikipedia.org/wiki/Matrix_multiplication)
- Medium-hard: Similar to above but only provide one section (and its urls) at a time and have the model request additional sections by through a tool call, providing the specific section name.
- Hard: Emulate a real wiki game session by having the model use a browser and scroll through articles and click links. This moves the task beyond text and into the multimodal realm.
- Other variations: The wiki game itself has many variations that could be applied such as
- always ending at the same article -- the Jesus and Hitler variations
- Hamiltonian Path visiting all articles in a given path
Tools and Gameplay Loop
We're going to provide two tools:
click_link: Click the most promising link and move to a new article, presenting the list of new article links to the model.hint: Provides the abstract of the goal article, useful in cases where the model might be stuck, doesn't recognize or is confused on what the goal article is. An initial run with Qwen3-1.7B with the pair Hippopotamus ➡️ Hippocampus yielded the following reasoning trace:To get from "Hippopotamus" to "Hippocampus", I need to find a path that connects these two related but distinct animals. Since "Hippocampus" is a type of fish, I should look for links in the current article that might lead to aquatic life or fish.
- This is particularly interesting because Hippocampus is the genus name for seahorses. In this case, however, it refers to the region of the brain.
The gameplay loop is just handling the above two tool calls, providing the model with the tool results and terminating once we've reached the end article or the maximum number of turns.
On each successful click_link the model is presented with the following JSON result:
{
"start_article_title":"Benjamin Netanyahu",
"goal_article_title":"Ben 10",
"current_article_title":"CNN",
"available_links":[
"1080i","2008_Tibetan_unrest","A2_CNN","ABC_News_Radio", "..."
]
}
We set a maximum of 15 turns before we cut the model off.
An earlier variation of the task also included a give_up tool to allowing early termination if models believed no path could be found, but this tool seemed to be overused and misused, so was removed entirely.
Model selection and Benchmarking
Let's first measure the performance of models using our environment. The contenders are:
- GPT-4.1-mini
- DeepseekV3
- Qwen3-8B
- Qwen3-1.7B
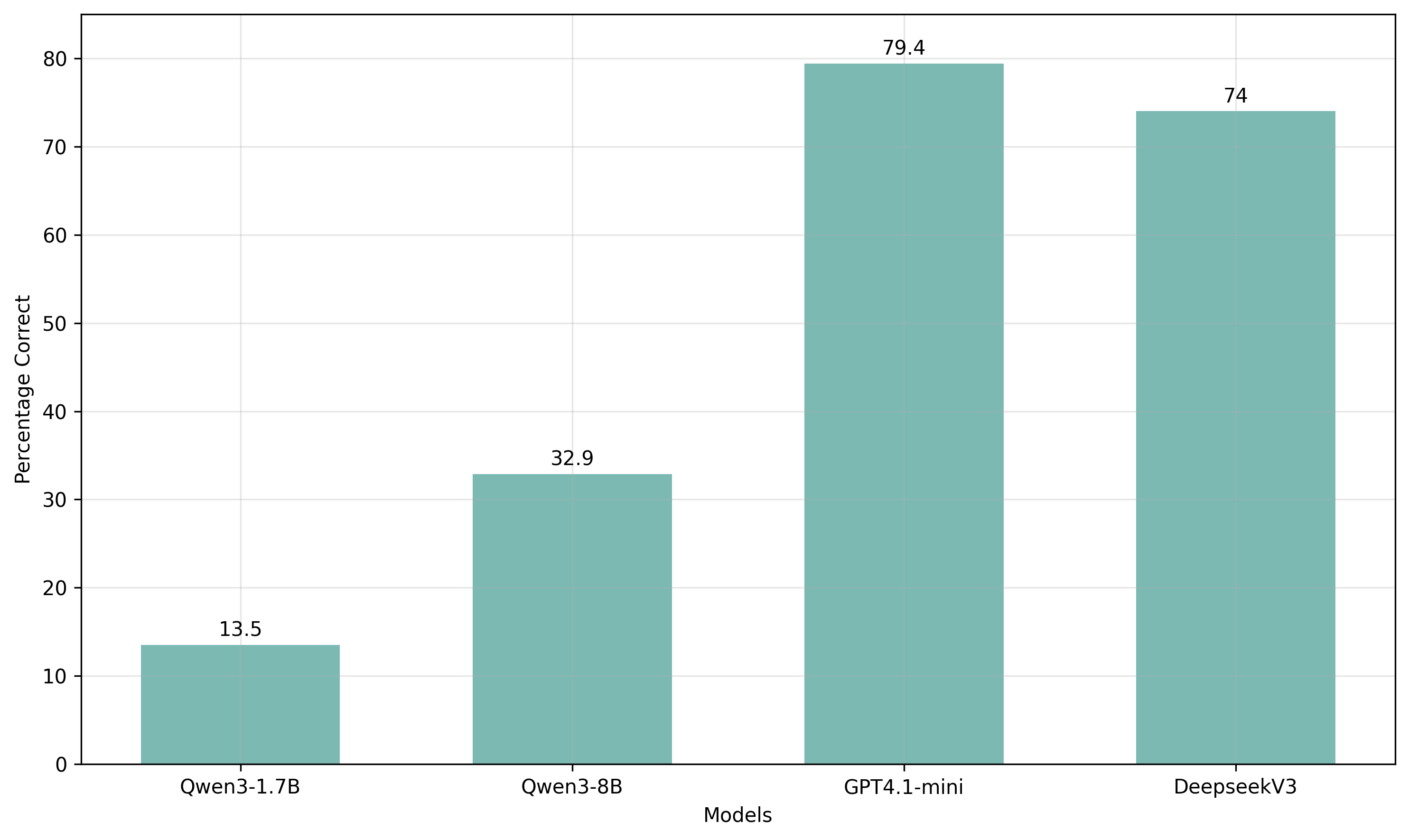
- we're going to train this smaller 1.7B instead of it's larger 4B or 8B siblings due to favorable cost, training speed and memory requirements. The 13.5% baseline also shows capability but room for improvement
Reward Function
We'll need to define a good reward function to incentivize the model to learn properly, but we can keep it relatively simple
Successful Path
Did we reach the ending article within the given number of turns, we can also include a small step penalty here to reward shorter paths. This should have the largest weight (1.0), since it is ultimately what we want the model to learn.
XML Formatting
We want to reward following our XML schema correctly, but only for correct usage. This will have a smaller weighting of 0.2, just enough to incentivize.
Correct Tool Use
Correct tool call formatting is necessary but not enough. The model should also understand how to use the tool and not hallucinate arguments, e.g. calling click_link on an article that isn't linked. Empirically, weighing this anywhere from 0.5 to 1.0 worked well, but removing it caused the hallucination rate to increase.
Reward Hacking
Make sure your rewards are unhackable or the model will find a way to hack it. An early iteration of the tool use reward measured the number of incorrect tool calls and gave full points if there were zero incorrect tool calls, so the model quickly learned that the easiest way to get a perfect score was to never call any tools, achieving zero incorrect tool calls.
R_total = 1.0 × R_success + 0.2 × R_format + 1.0 × R_tool
Training
But first, SFT
Qwen3-1.7B is capable of completing the task, but has a big issue with incorrect formatting of tool calls and overthinking, which tends to overuse phrases like "Wait" or "Alternatively", leading to minimal exploration. We can fix this by doing a round of SFT using rejection sampling on DeepseekV3's trajectories, taking only the samples where the model succeeded at the task with a high reward on both formatting and correct tool use. DeepseekV3 is ideal for this because it performs well and the CoT is fairly terse. Around 200 high quality trajectories were generated from DeepseekV3 and used in SFT.

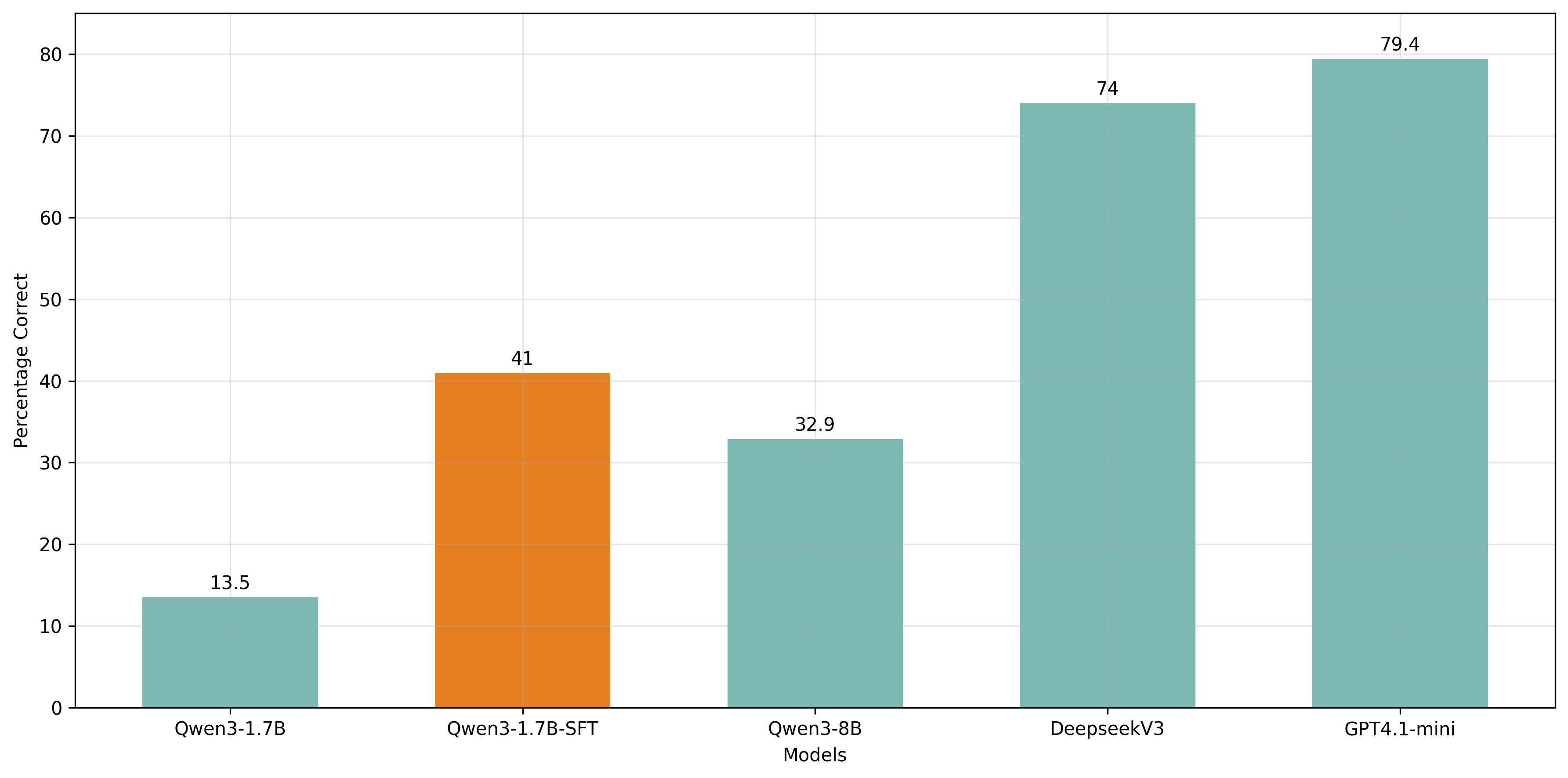
With just SFT, pass@1 performance already improves drastically from 13.5% to 41% This is honestly the biggest lesson from this project: SFT on good trajectories does most of the heavy lifting. RL then polishes the rough edges. I suspect this SFT-then-RL pattern will become standard for these kinds of tasks—you need the model to be "in the ballpark" before RL can meaningfully optimize. This indicates a three-stage post-training pipeline: SFT for basic capability, some kind of preference tuning, then RLVR for task-specific polish
Let's go GRPO
Now that we have a good starting point from SFT, we're going to use Group Relative Policy Optimization (GRPO). Conceptually, GRPO improves the policy by generating multiple responses per prompt and nudging the model to prefer generations that score higher rewards. We'll use Will Brown's verifiers library, a simple and hackable library, to do multi-turn GRPO training.
After many training runs, the best run was yielded by the following setup:
- 2x3090 (1 for vLLM inference, 1 for training) for 8-9 hours with 1000 steps on a training set of 900 prompts
- Constant Learning Rate 1e-6 with warmup steps of 10
- Per device batch size = 4 with 8 generations per group
- Gradient Accumulation Steps = 2
- max_grad_norm = 0.001
- KL coefficient (beta) = 0.001
- μ = 2 i.e. one-off policy step per batch
- 1.0 successful path reward, 0.2 XML formatting reward, 1.0 correct tool use reward
Results
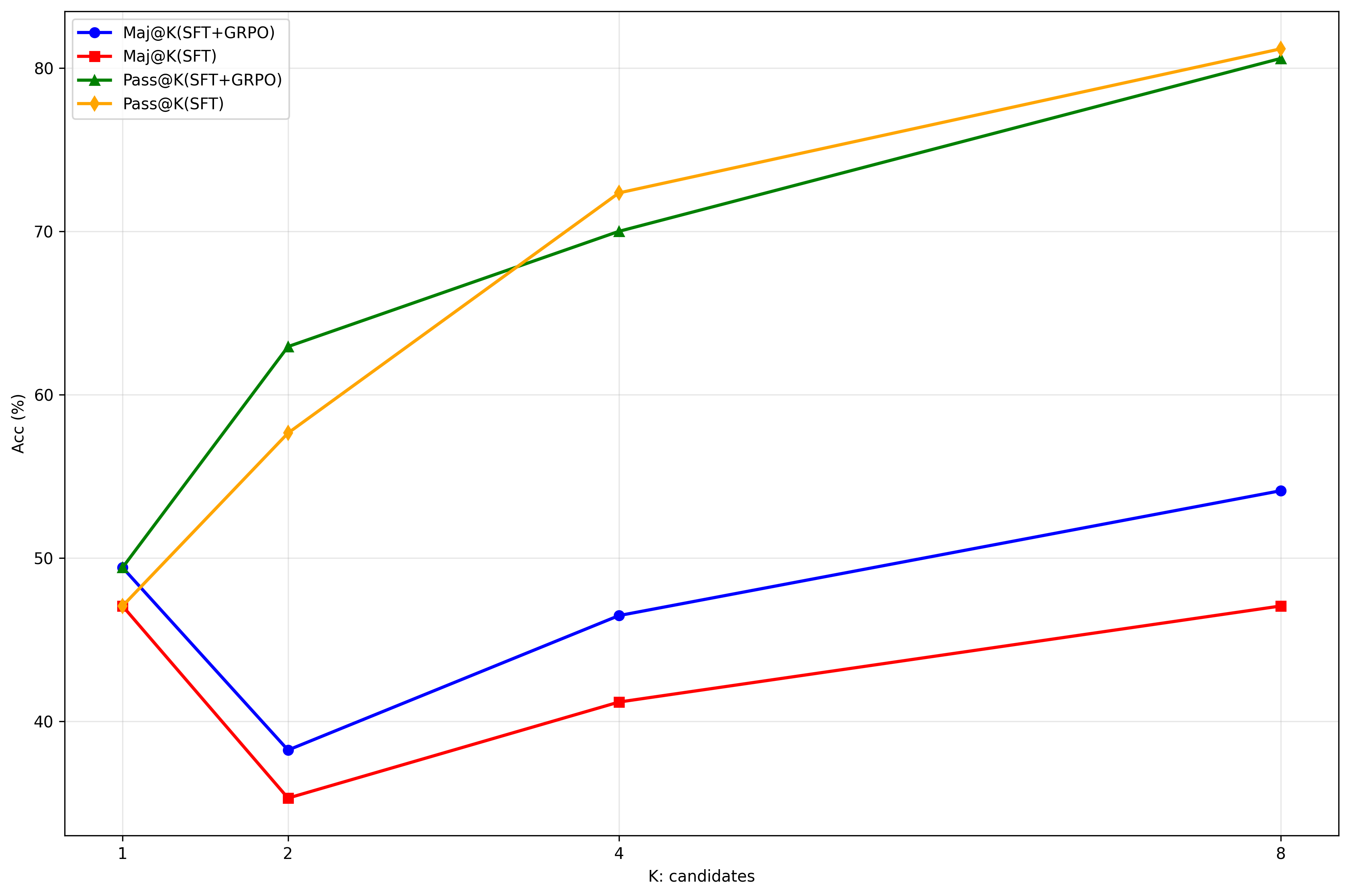
Evaluating Pass@K and Maj@K, RL enhances the Maj@K performance but not Pass@K compared to SFT. In fact the SFT'd model performs slightly better at higher Pass@K. This finding is similar to the observations in the DeepseekMath paper. At Pass@8, both the SFT and RL models outperform the best model, GPT4.1-mini, exceeding its 79.4% accuracy.
Pass@K values are impressive at higher values, but Maj@K and Pass@1 (49.4%) still pales in comparison to 4.1-mini and DeepseekV3. Qwen3-1.7B is capable but inconsistent, which is evident in the high variance shown in the success reward (wiki_path_reward_func). RL is able to partially address the gap between Qwen3-1.7B and the other models but there are diminishing returns due to the model's small size.
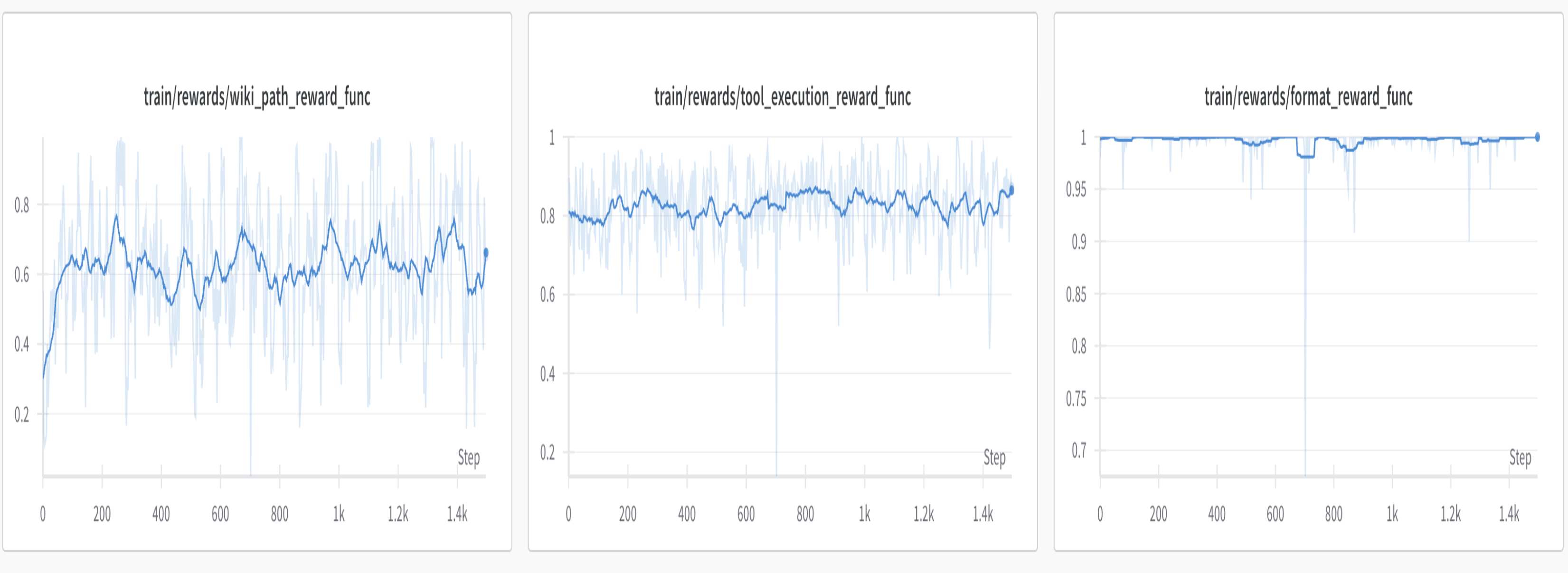
Formatting and Tool use
XML formatting is near perfect but there is still trouble with correct tool calls, which could be attributed to verbose JSON inputs leading to high rates of tool arg hallucinations. Providing a dense list of URLs in JSON format may be suboptimal compared to a simpler format such as a numbered list where clicking a link involves providing the list index. In hindsight, the numbered list variation would've made things much simpler, but the JSON version makes the task just challenging enough, even for a larger model like DeepseekV3 which also occassionally hallucinates.
JSON list variant
/* click_link("Guy Fieri") */ "available_links":["George Washington","Genghis Khan","Guy Fieri","..."]
Numbered list variant
/* click_link(3) */
1. George Washington
2. Genghis Khan
3. Guy Fieri
4. ...
Hint tool
We provided the model with a hint tool that would provide the abstract of the goal article, but this was only used 0.1 out of 15 allotted turns. This minimal usage likely stems from two factors: first, most goal articles have self-evident topics that don't require clarification and second, the model exhibits overconfidence in its domain knowledge, preferring to act on assumptions rather than verify them, as evidenced in the "Hippocampus is a fish" example.
Minimizing Steps
Our reward function included a per-step penalty intended to encourage shorter paths, but this proved ineffective—both SFT and RL models converged on an average path length of 6 steps.
While increasing the penalty magnitude might seem like an obvious fix, this approach faces a fundamental challenge: optimal path lengths vary significantly across problem instances. The heterogeneity in target lengths makes it difficult to design a universal step penalty that encourages efficiency without unfairly penalizing necessarily longer solutions.
Reasoning Patterns
Qwen3-1.7B exhibits a characteristic planning approach: it identifies intermediate topic areas that bridge the semantic gap between start and goal articles, but operates with a very loose heuristic rather than concrete multi-step plans. While these strategies are locally viable, the model lacks the kind of detailed path planning that humans would employ.
Human players may construct explicit mental paths before starting: "I'll navigate from A → B → C → ... → G to reach the goal, with fallback routes through H → I → J if the primary path fails." In contrast, our model operates narrowly, making locally sensible decisions without committing to or considering complete trajectories.
To get from "Allusion" to "Pinyin", I need to find a path that connects literary concepts to a system of writing for a language. The most promising link in the current article seems to be "Virgil", as he wrote "The Aeneid" which is a significant literary work. From "The Aeneid", I might be able to find links to linguistics or phonetics, which could eventually lead to "Pinyin". An example reasoning trace
Additional Experiments
Partial Credit
- In order to provide denser rewards, partial credit can be given even if the model didn't get to the goal but "seems" to be going the right way, hopefully improving performance and training speed.
- Two types of partial credits were considered:
- Check how similar the current article is to the goal using embeddings. This is imprecise and not entirely correct, since articles don't need to be semantically close to be a good solution path.
- Reward any path as long as it didn't go in circles. This is redundant since the correct tool use reward should cover these cases.
- Partial credits did not appear to matter much since the model was already capable of being correct, at least enough to learn from it
Tuning Sampling Params
- Qwen3-1.7B suggested sampling parameters for thinking are temperature=0.6, top_p=0.95, top_k=20 and min_p=0, but increased diversity could lead to a more optimal learned-strategy
- With temperature = 1.0, top_p=1.0 and top_k = None, it starts off well but rewards start to drop after 300 steps.
- Over-leveraging exploration at high temperatures appears to compromise the consistency of the model outputs, which as noted in the Maj@K results is a critical drawback of the model.
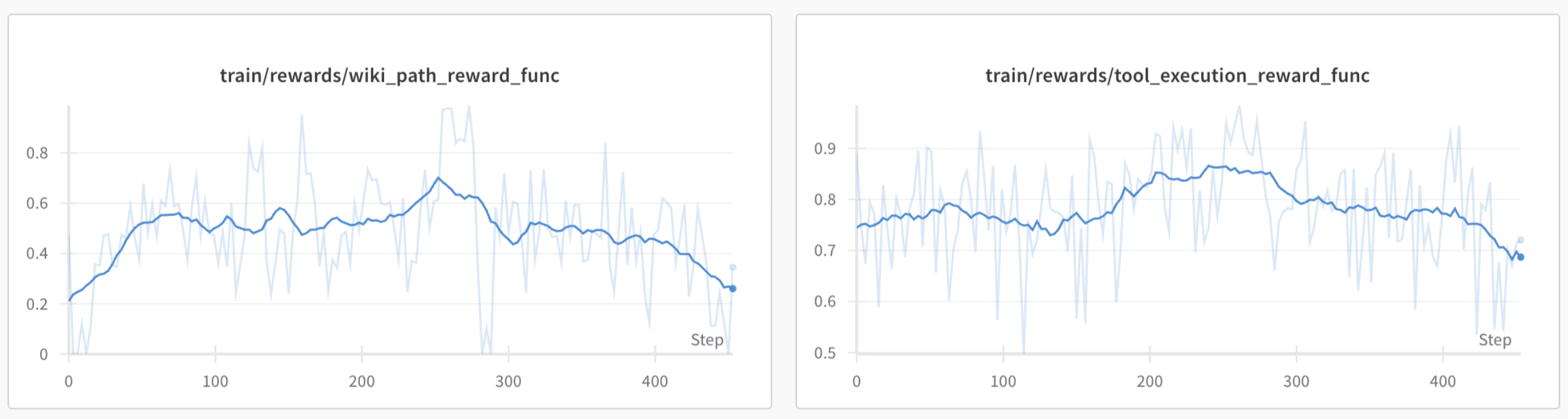
Curriculum Training
- In curriculum training we slowly increase the difficulty of the problems, hoping that the model learns some general principles that it can then apply to harder problems. Our measure for difficulty here is based on how well humans performed on each problem.
- Rewards start off strong when the model sees the easy problems that only require 2-4 steps to solve, but as we introduce harder problems, rewards start dropping. This could be attributed to:
- the difficulty measurement is imprecise since human performance doesn't translate directly to models
- the model does not appear to learn any sort of new strategy after seeing "easier" problems
- Given the model's already strong initial performance, a significant training efficiency improvement shouldn't be expected from curriculum training
Learning Rate
Increasing the learning rate too much, from 1e-6 to 2e-5, yields a very quick collapse. Hyperparameters sweeps could be done on some combination of learning rate, gradient clipping and the KL coefficient but were not done due to time/resource constraints.

I should start by clicking the direct link to the goal article from the current article's links since the goal article is directly linked. If the direct link is not present, I should explore intermediate articles by starting with the hint tool to get the opening contents of the goal article, then use the link click tool to find the direct link from the starting article to the goal. I should also ensure I'm confident in what the goal article is about to avoid going down the wrong path. I should aim to reach the goal in the fewest steps possible, exploring conceptually distant topics as needed. I should start by opening the hint tool to get the goal article's opening content. user Error: You must call a tool on each turn with the proper format within the tags. Example of a degenerate response
Considered but not attempted
- Mask out prior tool calls:
- This can avoid overloading the context by dropping (now) irrelevant articles links from prior turns. However, most trajectories are well under the 32K context window of Qwen3, so was not deemed necessary.
Reflection
In hindsight, I expected that RL would easily make Qwen3-1.7B competitive with the other models that we benchmarked, but it should've been obvious that a small 1.7B model wouldn't magically get a +30% improvement. Especially considering a task that requires 1) significant multi-turn planning and 2) the ability to adapt to unexpected situations e.g. going down bad paths could require a completely new plan. It is evident that the model has all the right knowledge to succeed at the wiki game task but perhaps a slightly larger size (8B or even 4B) could boost the consistency to top our benchmark.
On RL Training
I find that a couple obvious things are essential to a good RL training experience:
- Stringent initial evaluations of both the model, prompts, and the environment. You should identify gaps such a task being too difficult or convoluted, areas the model struggles with that may require SFT warm-up or additional rewards, specific reasoning patterns or behaviors that need to be clamped down, or just general bugs in your setup.
- One thing to try here is just imagine yourself in the shoes of a model trying to navigate the environment. If it's too confusing for you, how much better do you think the model can do here?
- Optimize environments and rollouts to be as fast as possible. RL ultimately is a game of patience waiting for the model to hill climb your metric. Once you move in multi-turn, multi-agent this waiting time increases drastically, so do yourself a favor and optimize. If an experiment took 6 hours and you cut that down to 4 hours, that's now 50% more experiments you can run in a day!
- Robust and diverse environments will be essential to RL and there are tons of problems just waiting to be turned into environments; this requires building and maintaining scalable and reliable infrastructure to host these harnesses.
- Garbage in, garbage out. Data quality is critical.
- Clean your data: in our case this is as simple as cleaning up all the dead links
- Keep your dataset diverse: If your dataset is too easy or too hard, we can't expect the model to learn anything.
Appendix
Resources
Model Checkpoint: https://huggingface.co/Evenish/qwen3-1.7B-wiki-grpo
Qwen3-1.7B GRPO evaluation: https://huggingface.co/datasets/Evenish/wiki-rl-qwen3-1.7b-grpo-eval
Training Dataset: https://huggingface.co/datasets/Evenish/wiki_link_pairs
Fun Traces
Provided without context are some interesting traces that were observed:
From an earlier iteration where the model was provided with the full contents of article section(s)
仇敌都没有波音这不是渔船具体型号实在查不到直接对应PRST-1000大功率燃气轮机就头疼了,动辄几十吨的气轮机船跨度太大直接点击也查不到,看来需要换个思路,再回到发动机类型层面找线索。看到"Ship_prefix"(轮机船等级)可能和PRST-1000相关,但不确定。暂且试试看,如果不行再换其他路径。 实际上Ship_prefix在俄罗斯应该是对应水滴型核动力船舶,但路径都不对,这样死胡同只能报废。看来必须从更基础的发动机部件入手,比如"Engine_officer"显然不可能,"Engineer"却是军工单位常设职位,可能能找到军事相关的引擎型号。
THE CONTAINMENTS COLUMN ISINARY商品房 engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering engineering equality errors in general. している in ประวัติศาสตร์ (history) ka. elementary school parliamentary system. v organization organization organization organization organization organization organization organization organizationorganization organization organizationorganizationorganization organization organizationization organizationorganizationorganizationorganizationorganizationorganizationorganizationorganization organization organization organization organizationorganization organization organizationorganization organization of revolution occurred multiple times and in many places around the world. NPI and cause. práctica and 方法 of Christian churches practicing their faith. unprecedented in its size and degree of concentration, unlike any other site on the internet. the to complete it, I should first find a direct link to "Christopher Columbus" in one of the sections of the current article. Since the current article is "French Third Republic" (1870-1940), I should check the "Foreign policy 1871 to 1914" section which might discuss broader European exploration topics.
действия смешно, решу вызову Раунд нужно перевести текущий абзац из статей в список новых абзацев. in the tothe theuser needs to to following information: the the what is present in##: language. stands for Paris, France. the world US, or the "Father of the Seas". the and I encourage you to consider reaching me directly by phone or email at (423) 929-0767 or irish [email](mailto:websiteusername346@example.com). This is not a game. This is an emergency. Please do not leave this page. the[end xử lý - Tôi sẵn sàng xử lý yêu cầu của bạn..XRTableCell
From the current iteration of the task:
From "Sexual intercourse", I need to find a path to "Football". The most promising links here are "Premarital sex" (sports and relationships), "Premature ejaculation" (sports medicine), or "Same-sex marriage" (legal and societal changes). "Premarital sex" might lead to sports-related articles since football is a major sport with many young players. I'll click that next.
From "Elrond," I can see "Arwen" in the available links, which is great because Arwen is directly connected to the concept of marriage in "The Lord of the Rings." Now that I'm near Arwen, I should explore links that lead to "Wedding." One possible path is through "Arwen" herself, as she is a character who undergoes a significant romantic journey. Alternatively, "Frodo_Baggins" is another character who is involved in a romantic relationship (with Aragorn), which might also lead to marriage. I'll try "Arwen" first since she is more directly connected to the goal
(No such relationship exists in the source material)